지난 시간에 살펴본 Linkedlist에는 치명적인 단점이 하나 있습니다.
Linkedlist를 사용하면 노드에 저장되는 다음 값의 메모리 주소를 바꾸어 연결을 수정하는 방식으로 효율적인 값 추가 및 제거가 가능합니다.
하지만 리스트의 다음 값으로는 넘어가기 쉽지만, 이전 값을 찾아 접근하기 어렵습니다.
Doubly-Linkedlist(이중 연결 리스트)는 이런 단점을 해결하기 위해 탄생했습니다.
Doubly-Linkedlist는 다음에 올 값의 메모리 주소와 함께, 이전 값의 메모리 주소를 저장해서, 앞뒤로 탐색이 가능합니다.
처음부터 시작해서 next를 이용해서 탐색하고, 후반부 절반의 엘리먼트는 마지막 노드부터 previous를 이용해서 조회합니다.
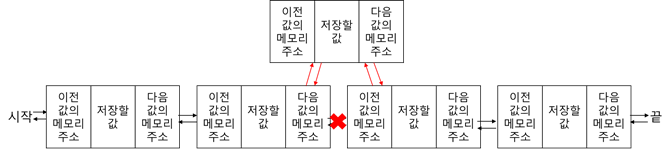
값을 추가할 때도 linkedlist와 마찬가지로 앞뒤 값의 메모리 주소를 참조하는 부분만 수정하면 됩니다.
다음 코드와 같이 node 클래스를 생성해서 틀을 잡았습니다.
package jaryogujo;
public class MyDoublyLinkedList {
private Node head;
private Node tail;
private int size;
public MyDoublyLinkedList() {
size = 0;
}
private Node getNode(int index) {
if (index < size / 2) {
Node node = head;
for (int i = 0; i < index; i++) {
node = node.nextNode;
}
return node;
} else {
Node node = tail;
for (int i = size - 1; i > index; i--) {
node = node.prevNode;
}
return node;
}
}getNode()메서드는 index 값을 받아 해당 위치의 node를 가져옵니다.
리스트 크기를 전반부와 후반부로 나누어, 이에 따라 검색 순서가 달라집니다.
public void addFirst(Object data) {
Node newNode = new Node(data);
if (head != null) { // 기존 노드가 있음
newNode.nextNode = head;
head.prevNode = newNode;
}
head = newNode;
if (head.nextNode == null) {
tail = head;
}
size++;
}
public void addLast(Object data) {
if (size == 0) {
addFirst(data);
} else {
Node newNode = new Node(data);
tail.nextNode = newNode;
newNode.prevNode = tail;
tail = newNode;
size++;
}
}addFirst() 메서드는 리스트의 맨 처음 부분에 데이터를 넣어주는 기능을, 반대로 addLast() 메서드는 리스트의 맨 마지막에 데이터를 넣어주는 기능을 합니다.
public void add(int index, Object data) {
if (index == 0) {
addFirst(data);
} else if (index == size - 1) {
addLast(data);
} else {
Node newNode = new Node(data);
Node prevNode = getNode(index - 1);
Node nextNode = prevNode.nextNode;
// 추가된 노드의 전후 설정
newNode.prevNode = prevNode;
newNode.nextNode = nextNode;
prevNode.nextNode = newNode; // 이전 노드의 전후 설정
nextNode.prevNode = newNode; // 다음 노드의 전후 설정
size++;
}
}Add()메서드는 원하는 위치 값에 해당하는 index와, 넣어줄 data를 받습니다.
새로운 노드를 만들어 data를 넣고, 앞 노드 값 prevNode를 index-1로 설정하고, 뒤 노드 값 nextNode를 prevNode 다음으로 지정합니다.
Index가 0이거나, size-1인 경우, 미리 만든 addFirst()나 addLast()를 타서 반복 연산을 피합니다.
public Object removeFirst() {
if(size == 0) {
return null;
}
Node removeNode = head;
head = null;
head = removeNode.nextNode;
head.prevNode = null;
size--;
return removeNode.data;
}
public Object removeLast() {
if(size == 0) {
return null;
}
Node removeNode = tail;
tail = null;
tail = removeNode.prevNode;
tail.nextNode = null;
size--;
return removeNode.data;
}removeFirst() 메서드는 맨 앞 노드를 지우고 데이터를 반환합니다.
반대로, removeLast()메서드는 맨 끝 노드를 지우고 데이터를 반환합니다.
public Object remove (int index) {
if (size == 0) {
return null;
} if(index == 0) {
return removeFirst();
}else if(index == size-1) {
return removeLast();
}else {
Node removeNode = getNode(index);
Node prevNode = removeNode.prevNode;
Node nextNode = removeNode.nextNode; // 이전 노드 전후 설정
prevNode.nextNode = nextNode; // 다음 노드 전후 설정
nextNode.prevNode = prevNode;
size--;
return removeNode.data;
}
}Remove()메서드는 index값을 받습니다.
리스트의 크기가 0인 경우 삭제를 수행하지 않고 null 값을 반환합니다.
Index 값이 0인 경우에는 removeFirst()메서드를, size-1인 경우에는 removeLast()메서드를 수행합니다.
그리고 그 외의 값들인 경우 노드의 연결을 변경하고 사이즈를 줄여서 삭제를 수행합니다.
public static void main(String[] args) {
MyDoublyLinkedList list = new MyDoublyLinkedList();
list.addFirst(40);
list.addFirst(30);
list.addFirst(20);
list.addFirst(10);
다음과 같이 새로운 리스트를 만들어 addFirst() 메서드를 활용하여 값들을 추가했습니다.
그 결과가 다음과 같습니다.

list.add(2, 25); // 10 20 25 30 40
2번지에 25를 추가한 결과가 다음과 같습니다.

이 리스트의 맨 끝에 50을 추가합니다.
list.addLast(50);

리스트의 맨 처음 요소를 제거합니다.
list.removeFirst();

리스트의 맨 마지막 요소를 제거합니다.
list.removeLast();

리스트의 1번지를 제거합니다.
list.removeLast();

다음과 같이 DoublyLinkedlist의 장단점을 요약할 수 있습니다.

단점에 비해 장점이 크기 때문에, 시간 복잡도나 편의성의 측면에서 Arraylist나 LinkedList를 사용할 특별한 이유가 없다면 이중 연결 리스트 역시 많이 사용됩니다.
이전 2개 편에서 알아본 내용 포함, 총 3가지 리스트의 성능에 대하여,
시간 복잡도(big-O 표기법)를 사용하여 장단점을 비교할 수 있습니다.
연산과정에서 가장 시간이 오래 걸리는(최악의) 경우일 때를 기준으로 하며, 시간을 계산하는 수식이 복잡해질 경우 최고차 항을 기준으로 합니다.
O(1) < O(log n) < O(n) < O(nlog n) < O(n^2) < O(n^3) < O(2^n) < O(n!) 순으로 복잡합니다.
데이터를 추가하는 보통의 경우를 생각하면, 최악의 경우 리스트 끝까지 탐색해야 합니다.
이런 식으로, 발생할 수 있는 추가/삭제/탐색 경우의 수에 대한 시간복잡도를 아래 표로 정리했습니다.
| 구분 | ArrayList | Linkedlist | doublylinkedlist |
| add(끝) | O(1) | O(n) | O(1) |
| add(시작) | O(n) | O(1) | O(1) |
| add(일반적인 경우) | O(n) | O(n) | O(n) |
| get/set | O(1) | O(n) | O(1) |
| indexOf/lastIndexof | O(n) | O(n) | O(n) |
| isEmpty/size | O(1) | O(1) | O(1) |
| remove(끝) | O(1) | O(n) | O(1) |
| remove(시작) | O(n) | O(1) | O(1) |
| remove(일반적인 경우) | O(n) | O(n) | O(n) |
다음 시간에는 hashmap에 대해 알아보겠습니다.
'study > Java' 카테고리의 다른 글
| Stack(push/pop) (0) | 2021.08.27 |
|---|---|
| Hashmap / Treemap (0) | 2021.08.26 |
| Linkedlist에 대해 알아보자 (0) | 2021.08.24 |
| 컬렉션 프레임워크: Arraylist (0) | 2021.08.23 |
| 기본형/참조형 매개변수 (0) | 2021.08.22 |




댓글